Womit verbringt eine Person, deren Spezialgebiet die Datenanalyse ist, die meiste Zeit? Sicherlich wird jeder, der kein Datenanalyst ist, antworten, dass es seine Aufgabe ist, Daten zu analysieren und die Ergebnisse zu präsentieren. In einer idealen Welt wäre dies sicherlich der Fall, und die Berichterstattung wäre eine leichte und angenehme Tätigkeit. Was ist dann das Beunruhigendste für jeden Analysten? Um mit einem Wort zu antworten: Datenaufbereitung.
Jeder Analyst möchte sicherlich saubere Datensätze erhalten, mit standardisierten Spaltennamen. Ebenfalls lästig für Analysten sind ungewöhnliche und Ausreißerwerte, die nicht überall ausgefüllt sind. Nach der Bewältigung dieser Probleme bleibt nur noch, weitere Visualisierungen zu erstellen, deren Ergebnisse zu interpretieren und am Ende des Tages Ihre Vorgesetzten mit tief verborgenen Erkenntnissen, noch nie dagewesenen Entdeckungen und wertvollen Empfehlungen zu überraschen. Unser Unternehmen erreicht dann ein Wachstum, das weit über dem des Marktes liegt. Nach einiger Zeit wird er zum Weltmarktführer, und der Analytiker – eine lebende Legende. Eine schöne Vision, aber die Welt sieht anders aus. Warum ist es so schwer, gute Daten zu finden, denen man vertrauen kann? Das Problem tritt sehr oft in der Anfangsphase der Datenanalyse auf.
Herausforderungen für den Datenanalytiker
Die größte Herausforderung für jeden Spezialisten mit Schwerpunkt in der Datenanalyse besteht in der Handhabung, Transformation und Vorbereitung des Datenbestands für die Analyse. Leider werden Daten, die Ereignisse in einem Unternehmen beschreiben, immer eine angemessene Verwaltung erfordern – Kontrolle ihrer vollständigen und korrekten Erfassung, Behandlung von ungewöhnlichen Vorfällen, Implementierung von neuen Informationsstrukturen. Der Umfang dieser Aufgabe erzwingt oft die Schaffung einer separaten Position, die für das Data Engineering verantwortlich ist – ihre Aufbereitung, die Planung der Berichtsstruktur und die technologische Architektur hinter dem gesamten Prozess.
Unabhängig von der Größe unseres Unternehmens, der Struktur der Analyseabteilung und der Qualität der Daten sollte jedoch jede Datenanalyse mit der Vorbereitung des Analysesets und seiner Visualisierung beginnen. Hier kommt die explorative Datenanalyse (EDA – Exploratory Data Analysis) ins Spiel. Es handelt sich um einen Prozess, der zu Beginn der Arbeit des Analysten durchgeführt wird und der es ihm ermöglicht, sich mit der bestehenden Struktur vertraut zu machen und mögliche Probleme zu behandeln. In dieser Phase erwirbt der Analytiker Informationen über die Sammlung selbst, beginnt sie zu verstehen, bemerkt ungewöhnliche Werte oder Fehler in der Sammlung, die zusätzliche Maßnahmen erfordern. Worin besteht der Prozess der explorativen Datenanalyse?
Lernen Sie in 5 einfachen Schritten, wie Sie Daten für eine effektive Analyse und Visualisierung der Ergebnisse richtig vorbereiten.
Datenanalyse und ihr wirtschaftlicher Sinn – verstehen Sie Ihren Datenbestand?
Der Schlüssel zur Datenanalyse ist es, zu prüfen und zu verstehen, womit wir es zu tun haben. In diesem Stadium sollten wir folgende Fragen beantworten:
- Woher kommen die Daten: wer erfasst sie, wann, wie?
- Was genau bedeutet jede Spalte/Variable/Tabelle (z. B. ist das „Datum, an dem ein Mitarbeiter hinzugefügt wurde“ das Datum, an dem er eingestellt wurde, das Datum, an dem er dem System hinzugefügt wurde, das Datum, an dem er zu arbeiten begann)?
- Welche Werte finden sich in den einzelnen Abschnitten der Datensammlung (z.B. ist die Spalte mit dem Einstellungsdatum des Mitarbeiters nur ein gültiges Datum oder vielleicht auch Zahlen und Sätze)?
- Was möchte ich letztendlich erhalten (ist dieser Datensatz für eine erfolgreiche Datenanalyse geeignet)?
Es mag den Anschein haben, dass die Antworten auf diese Fragen offensichtlich sind und diese Phase nur eine Formalität ist. Leider ist das aber oft ein sehr mühsamer Schritt. An verschiedenen Stellen im Datensatz können Werte erscheinen, die wir nicht verstehen, daher ist es notwendig zu erklären, warum solche Werte vorkommen und was sie bedeuten. In diesem Stadium können wir z. B. erfahren, dass die Variable, die dem Transaktionswert entspricht, neben Zahlen auch Ausdrücke wie „storniert“, „unbekannt“, “ in Raten“ enthält.
Es kann sich auch herausstellen, dass ein Teammitglied, das in die USA versetzt wurde, die Vertragsdaten im Format MM/TT/JJJJ eingetragen hat, während der Rest des Teams – TT/MM/JJJJ. Folglich beinhaltet diese Phase der Analyse sowohl eine vorläufige Analyse der Sammlung in einem Analysewerkzeug (Business-Intelligence-Tools wie Tableau, IDEs wie PyCharm usw.) als auch eine gründliche Überprüfung der Metadaten der Sammlung und einen gemeinsamen Vergleich unserer Ergebnisse mit denen des Teams, um alle Zweifel zu klären.
Wenn dieser Schritt korrekt ausgeführt wird, sollten wir Informationen über die notwendigen Transformationen an den Daten im Datensatz erhalten, deren Durchführung für die weitere Analyse notwendig ist.
Optimieren Sie Ihren Datenbestand
Im zweiten Schritt des Prozesses sollten wir uns auf die technische Optimierung des Sets konzentrieren. Das bedeutet, dass Sie für jede untersuchte Spalte/Variable/Tabelle zwei Fragen beantworten müssen:
- Ist das angegebene Objekt (z. B. Tabelle, Spalte, Variable) für diese Analyse nützlich (wenn nicht, sollte es entfernt werden)?
- Hat das Objekt den richtigen Datentyp (z. B. sind die Zahlen eindeutig integer/float und nicht string)?
Dieser Schritt ist zwar einfach in der Durchführung, aber extrem wichtig. Bei mittleren und großen Datensätzen kann es die Arbeit an ihnen sogar um ein Vielfaches beschleunigen. Wenn die Datenanalyse auf einer flachen Tabelle durchgeführt wird, die mehrere tausend Datensätze und mehrere Dutzend Spalten enthält, kann dieser Schritt ihre Größe sogar um das Zigfache reduzieren. Dies schlägt sich in der Analysezeit nieder. Das Erzeugen eines einfachen Diagramms dauert eine statt etwa einem Dutzend Sekunden, und die Ausführung eines vollständigen Analyseskripts dauert etwa eine statt etwa 10 oder 20 Minuten. Obwohl dies keine großen Zahlen sind, sollte man bedenken, dass das Erstellen und Testen eines Skripts voraussetzt, dass es mehrmals ausgeführt wird…
In diesem Stadium führen wir eine Transformation der verfügbaren Daten durch. Dies ist eine einfache Aufgabe, die in den meisten Analysetools durchgeführt werden kann. Bei diesem Schritt ist es wichtig, die von unserer Analyseumgebung unterstützten Datentypen im Auge zu behalten und immer darauf hinzuarbeiten, den benötigten Speicherplatz zu minimieren.
Vermeiden Sie die „speicherintensivsten“ Typen, wie z. B. String (Wörter, Tasks, Zeichenketten). Wählen Sie stattdessen die speichereffizientesten, wie z. B. boolean (wahr/falsch).
Datenlücken angemessen behandeln
Der nächste Schritt in der Datenaufbereitung ist die ordnungsgemäße Handhabung von fehlenden Daten in der Datenbank. In jeder produktiven Datenbank werden wir auf Situationen stoßen, in denen der Wert eines bestimmten Objekts leer ist. Der klassische Fehler in einem solchen Fall ist die Zuweisung von Null zu diesem Wert. Das Fehlen von Daten in ausgewählten Zellen bedeutet jedoch nicht, dass der Wert an dieser Stelle Null ist und es keine Grundlage für eine solche Aktion gibt. Was ist außerdem, wenn in der Spalte ein Datum oder eine Produktbeschreibung stehen soll, aber keine Nummer? In diesem Fall können wir erst recht nicht die Fehlstellen durch Null ersetzen.
Im ersten Schritt ist es notwendig, die Art der auftretenden Fehler aufgrund ihrer Genese zu bestimmen. Auf diese Weise können wir unterscheiden:
- menschliche Fehler (ein bestimmter Wert hätte ausgefüllt werden müssen, aber die dafür zuständige Person hat es nicht getan);
- echte Mängel (aufgrund der Spezifität des Datensatzes sollte der Wert tatsächlich leer sein, z. B. sollte der Wert der Variablen „kürzlich gekauftes Produkt“ leer sein im Falle eines Kunden, der noch keinen Kauf auf unserer Plattform getätigt hat).
Bei echten Fehlern hängt die Art und Weise, wie sie behandelt werden, von unserer Analyse ab. Meistens werden Datensätze mit Mängeln jedoch nicht verändert und bei der Darstellung der Ergebnisse als eigene Kategorie von Datensätzen behandelt. Das ist richtig, aber einige Analysen sind mit ihrem Set nicht möglich.
Mängel, die durch menschliches Verschulden entstehen, bedürfen einer Absprache zur Behandlung im Team/Management. Zu den Möglichkeiten gehören:
- Definieren eines Wertes, der die fehlenden Daten ersetzt (z. B. fügen wir im Voraus das Datum 01.01.2000 ein für jedes fehlende Feld „Beschäftigungsdatum“ oder den durchschnittlichen Auftragswert für das fehlende Feld „Auftragswert“. Alternativ können fehlende Daten gemäß den Verteilungen der Variablen ersetzt werden)
- Manuelles Auffüllen der Lücken mit entsprechenden Werten durch die dafür verantwortlichen Teammitglieder (was möglicherweise nicht möglich ist, wenn der Umfang der Lücken erheblich ist oder sie zeitlich weit entfernte Ereignisse betreffen)
- Lücken zu lassen (wenn ihr Auftreten die Analyse nicht wesentlich beeinflusst)
- Entfernen fehlerhafter Datensätze aus der Analyse (was den Verlust einiger Informationen bedeutet, aber manchmal notwendig sein kann, wenn die Mängel die Realität erheblich verzerren können).
Bestimmen Sie die Verteilungen der Variablen und identifizieren Sie Ausreißer
Nachdem die Daten gemäß den in den vorherigen Schritten beschriebenen Prinzipien ordnungsgemäß bereinigt wurden, ist es an der Zeit, ihre Struktur besser zu verstehen. Wir wissen jetzt z. B., dass die Werte, die den Zahlungsverzögerungen bei Rechnungen entsprechen, ganze Zahlen sind, die der Anzahl der Tage der Verspätung entsprechen. Doch wie setzen sich diese Werte in Bezug auf die Häufigkeit/Dichte des Auftretens zusammen? Verspätet sich der Kunde am häufigsten um maximal eine Woche? Sind diese Werte in unserem Fall gleichmäßig über das ganze Jahr verteilt? Gibt es Ausreißer, d.h. Kunden sind in der Regel höchstens eine Woche im Verzug, ein Auftragnehmer aber 600 Tage?
Ein Blick auf die Daten
Als Teil dieser Phase müssen wir ein Dichteplot oder ein Histogramm für jedes untersuchte Objekt erstellen. Unten ist ein Beispiel für eine Analyse der in einem bestimmten Geschäft angebotenen Rabatte. Solche Visualisierungen helfen uns zu verstehen, wie unsere Werte verteilt sind und wo wir das Auftreten von abnormalen Werten erwarten können.
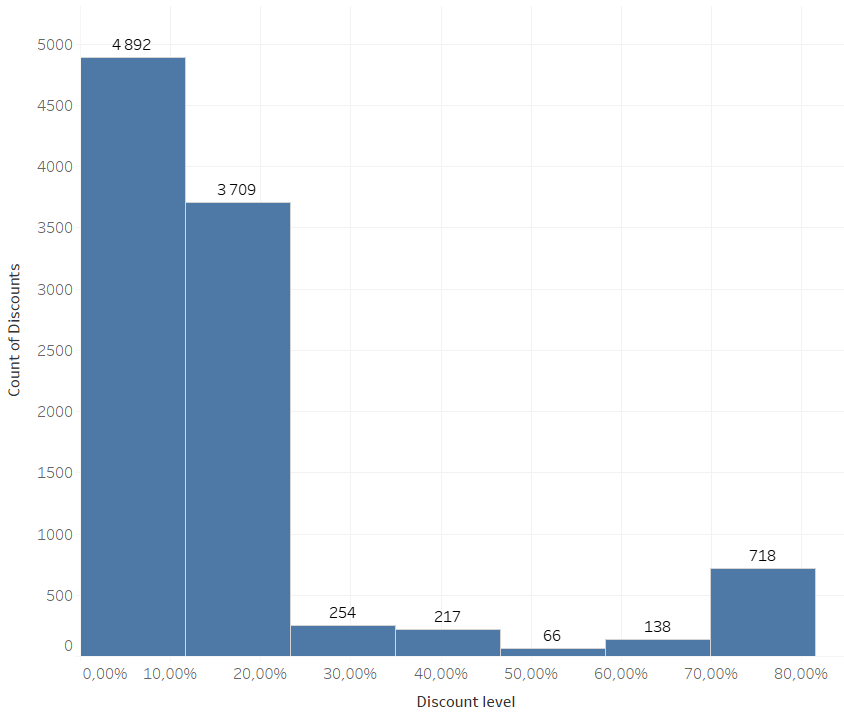
Am Beispiel des obigen Diagramms können wir sehen, dass die Skala der Preissenkungen nicht symmetrisch ist. Es dominieren kleine Preisnachlässe. Gleichzeitig liegen erhebliche Rabatte (im Bereich von 70-80%) auf dem dritten Platz in Bezug auf Häufigkeit. Dies kann auf die Strategie des Unternehmens in Bezug auf Rabatte hinweisen, nach der der Rabatt klein oder signifikant sein sollte. Das liegt daran, dass Rabatte in der Mitte des Tarifs nicht auffallen und gleichzeitig Geld kosten.
Nach einer solchen Analyse sollten weitere Statistiken für jedes Objekt überprüft werden, wie z. B. Mittelwert, Median, Standardabweichung, Werte für das erste und dritte Quartil. Um sie einfach zu interpretieren, können Sie ein Boxplot (Diagramm unten) verwenden, das einige dieser Statistiken zeigt.
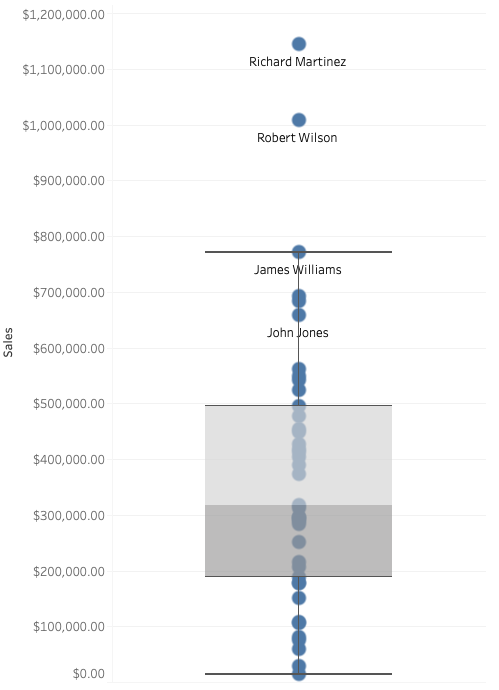
Aus dem obigen Diagramm können wir ablesen:
- den Median (die Grenze der beiden grauen Rechtecke in der Mitte),
- das erste und dritte Quartil (die untere und obere äußere Grenze der beiden grauen Rechtecke)
- den Interquartilsbereich (die Länge der beiden grauen Rechtecke),
- erstes und drittes Quartil, wobei der Wert der vierteljährlichen Spanne subtrahiert bzw. addiert und mit 1,5 multipliziert wird (die äußersten horizontalen Linien, die so genannten „Whisker“; im Fall dieser Grafik endet die untere Grenze bei Null, da der Umsatzwert nicht negativ sein kann)
- die Ergebnisse der einzelnen Händler (Punkte).
Aus dem Beispieldiagramm können wir erkennen, dass sich zwei Verkäufer in Bezug auf den Umsatzwert von den anderen abheben: Richard Martinez und Robert Wilson. Gleichzeitig sind ihre Ergebnisse nicht unplausibel, so dass es keinen Grund gibt, einen Fehler in den Daten zu vermuten.
Schlussfolgerungen aus der oberflächlichen Analyse
Obwohl in diesem Stadium bereits typische analytische Arbeiten auftreten, Grafiken und Statistiken erstellt werden, sollte dieses Element nicht als vollständige Datenanalyse behandelt werden. Diese Phase dient nur dazu, den Untersuchenden mit den Eigenschaften des Datensatzes vertraut zu machen und ihm zu ermöglichen, mögliche Transformationen noch vor der eigentlichen Analyse vorzunehmen.
Gleichzeitig sollten wir in dieser Phase entscheiden, wie wir mit Ausreißern umgehen. Zum Beispiel für den erwähnten Fall eines Zahlungsverzugs der Rechnung von 600 Tagen. In der Literatur kann man auf einen Ansatz stoßen, der die Verwendung der „Drei-Sigma-Regel“ vorschlägt. Dieser Begriff bedeutet, dass alle Beobachtungen zurückgewiesen werden, die mehr als drei Standardabweichungen vom Mittelwert entfernt sind.
Beachten Sie jedoch, dass dieser Ansatz nur für eine normale Wahrscheinlichkeitsverteilung gültig ist, bei der tatsächlich 99,7 % der Beobachtungen im Bereich: Mittelwert +/- drei Standardabweichungen liegen. In der Realität können wir das Vorhandensein dieser Verteilung in unseren Daten nur selten bestätigen. Ein klassischer Fehler bei der Anwendung dieser Regel ist z. B. Kunden mit Einkaufswerten außerhalb des oben angegebenen Bereichs von der Analyse auszuschließen. Ein solch hoher Wert verzerrt die Analyse, kann aber gleichzeitig darauf hinweisen, dass es sich bei dem betreffenden Käufer um einen Geschäftskunden und nicht um einen Privatkunden handelt. Folglich sollten sie nicht ausgeschlossen, sondern separat analysiert werden, in einer Untergruppe von Datensätzen, die Unternehmen entsprechen.
Daher ist der beste Ansatz für den Umgang mit Ausreißern, jede Variable einzeln zu betrachten und entsprechend ihrer Verteilung, Statistik und Aussagekraft zu entscheiden. Wie bei fehlenden Daten können wir entscheiden, ob wir diesen Wert durch einen anderen ersetzen, ihn aus der Menge entfernen oder ihn unverändert lassen.
Beziehungen und Korrelationen zwischen Variablen prüfen
Der letzte Schritt der ordnungsgemäß durchgeführten explorativen Datenanalyse besteht darin, die Beziehungen und Korrelationen zu prüfen, die zwischen den untersuchten Variablen bestehen. Dieser Schritt setzt die Überprüfung des gemeinsamen Auftretens von gegebenen Kategorien und Werten bestimmter Variablen in unserem Datensatz voraus.
Die grundlegende Aktivität in dieser Phase besteht darin, Korrelationsmaße zu bestimmen. Im klassischsten Fall ist dieses Maß der lineare Korrelationskoeffizient nach Pearson, der angibt, ob z. B. bei einem Anstieg des Wertes der einen Variablen der Wert der anderen Variablen steigt oder sinkt. Alternativ, z. B. bei einer Variable mit Ausreißern, kann der Spearmansche Rangkorrelationskoeffizient verwendet werden, der in einem solchen Fall Abhängigkeiten besser wiedergibt.
Die Korrelations- und Koinzidenzanalyse ermöglicht es uns, die Gültigkeit und Konsistenz unserer Daten mit der Intuition zu überprüfen. Wenn die Analyse zeigt, dass höhere Ordnungswerte bei einzelnen Kunden und nicht bei Unternehmen gefunden werden, kann dies auf Fehler im Set hinweisen, die auf keiner der vorherigen Analyseebenen erkannt wurden. Gleichzeitig ist dies die Phase, in der wir bereits die ersten Abhängigkeiten angeben können. Auf diese Weise können wir nahtlos zur richtigen Analyse des bereits sauberen Datensatzes übergehen.
Die korrekte Ausführung der oben genannten Schritte verkürzt die analytische Arbeit an der Kollektion erheblich. Dank der folgenden Schritte kann der Forscher die Daten, d.h. das Material, an dem er arbeitet, gründlich verstehen. Dadurch werden viele Fehler und Missverständnisse in den nachfolgenden Schritten vermieden, und die Datenanalyse wird effektiv durchgeführt.
Wir laden Sie auch dazu ein, uns auf LinkedIn oder XING zu folgen.
Artikel von Karol Michalak.








































{kind=link}
{kind=link}
{kind=link}
{kind=link}